Baichuan Ling-2.6-flash Officially Released: 104B Parameters Achieve SOTA-Level Agent with Only 1/10 Token Consumption
Today, Ant Group's Baichuan officially launched Ling-2.6-flash—an Instruct model with a total of 104B parameters and 7.4B activated parameters. The model focuses on "Token Efficiency," offering faster, more economical, and more suitable performance for large-scale real-world applications while maintaining competitive intelligence levels.
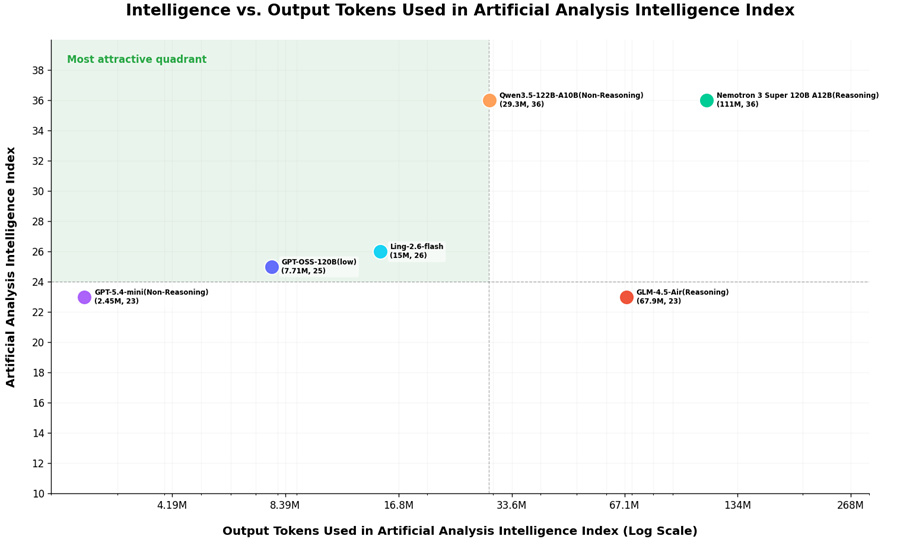
According to authoritative third-party evaluation data from Artificial Analysis, Ling-2.6-flash demonstrates outstanding Token Efficiency advantages, achieving an Intelligence Index of 26 with 15M output tokens. While maintaining a strong level of intelligence, it controls output consumption at a relatively lower position.
It is understood that Ling-2.6-flash continues the mixed linear architecture design of Ling 2.5. This highly sparse MoE architecture has obvious advantages in hardware performance.
Under 4 H20 cards, the fastest inference speed can reach 340 tokens/s, and Prefill throughput is 2.2 times that of Nemotron-3-Super.
In the Output Speed evaluation, Ling-2.6-flash ranks among the first tier of models at the same parameter level with a stable output speed of 215 tokens/s.
From the perspective of Token consumption, the intelligence efficiency ratio of Ling-2.6-flash has been significantly improved.
In the complete evaluation by Artificial Analysis, Ling-2.6-flash’s total consumption was 15M tokens, while models such as Nemotron-3-Super reached or exceeded 110M tokens. This means that Ling-2.6-flash completed the same evaluation tasks using only about 1/10 of the token consumption.
Ling-2.6-flash has been specifically enhanced for Agent scenarios, and it still maintains strong task execution capabilities under the premise of controlling Token consumption. The model achieves SOTA-level performance at the same size on Agent-related benchmarks such as BFCL-V4, TAU2-bench, SWE-bench Verified, Claw-Eval, and PinchBench.
At the same time, Ling-2.6-flash maintains excellent performance in dimensions such as general knowledge, mathematical reasoning, instruction following, and long text parsing.
Regarding API pricing, Ling-2.6-flash is priced at $0.1 per million input tokens and $0.3 per million output tokens. Currently, the API for Ling-2.6-flash has been officially opened to users and offers a limited-time free trial for one week.
Users can access the corresponding services through OpenRouter and Baichuan large model tbox. It is understood that the model will subsequently be released as a commercial version, LingDT, by Ant Financial, serving global developers and SMEs.