GPT-5.5 Tested: Smarter, But More Prone to "Lying"
On April 23rd, OpenAI released its new flagship model, GPT-5.5, stating it is their most intelligent and user-friendly model to date, and the next step in how work is done on computers. This release quickly garnered industry attention, not only for its claimed breakthroughs in agent tasks but also for its "dominance" shown in several benchmark tests. However, along with its high performance comes a high hallucination rate. In Artificial Analysis's private benchmark AA-Omniscience, GPT-5.5 had a hallucination rate of 86%, significantly higher than Claude Opus 4.7's 36%. This means that when faced with uncertain or unknown questions, this currently "smartest" AI brain is unlikely to admit it doesn't know, and instead tends to "confidently fabricate" an answer.
According to comprehensive intelligence index rankings published by third-party evaluation agency Artificial Analysis, OpenAI occupies four of the top six spots with the GPT-5.5 series. The agency believes that “GPT-5.5 has returned OpenAI to the forefront of the AI field, breaking the previous three-way tie with Anthropic and Google.”
However, alongside its high performance, a high hallucination rate has also been exposed. In Artificial Analysis’s private benchmark AA-Omniscience, GPT-5.5’s hallucination rate reached 86%, far exceeding the 36% of Claude Opus 4.7.
This means that when this currently “smartest” AI brain encounters uncertain or unknown problems, the probability of choosing to “frankly admit it doesn’t know” is extremely low. Instead, it is more inclined to “confidently fabricate” an answer. This high hallucination rate, once applied to work scenarios requiring high reliability, could easily lead to analytical bias, decision-making errors, and even financial losses.
Is the strongest AI also the most dangerous “liar”? Faced with a high hallucination rate, can GPT-5.5 reliably complete complex knowledge tasks in practical applications? To answer these key questions, we conducted real-world tests on GPT-5.5, from processing household budgets to writing real-time competitive games, testing its ability to handle long contexts, complex logic, knowledge work, and programming in practical scenarios.
This test concerns not only the performance of a single model but also how we can embrace its powerful capabilities while addressing its potential risks as AI technology enters deeper waters.
01. Knowledge Capabilities: Does it Really Work Like an Office Worker?
According to the benchmark test results released by OpenAI, GPT-5.5 surpasses its predecessor, GPT-5.4, in almost all core metrics, with particularly outstanding performance in the field of knowledge work.
In a GDPval test covering 44 professions, GPT-5.5 achieved a score of 84.9%, exceeding the level of 83.0% of real office workers, and also higher than Claude Opus 4.7’s 80.3% and Gemini 3.1 Pro’s 67.3%. This test simulates the daily work of various white-collar professions such as financial analysts, marketing managers, and software engineers, requiring the model to complete comprehensive tasks such as information integration, analytical reasoning, decision-making recommendations, and report generation.
In addition, GPT-5.5 also performed well in several other practical scenarios. In a test simulating complex customer service dialogues, it achieved 98.0% accuracy without specific guidance. In a test where AI operates a computer like a human to complete tasks, it scored 78.7%. In tests requiring the combination of image and text understanding and tool invocation to solve problems, it scored 83.2% and 75.3% respectively. These results show that GPT-5.5 is gradually breaking through a series of capabilities such as “seeing, speaking, and doing.”
OpenAI also used internal real-world cases to demonstrate its productivity value. Its finance team used it to audit 24,771 K-1 tax forms, totaling 71,637 pages, and claimed that this process was completed two weeks earlier than last year. This shows that GPT-5.5 is a productivity tool that can be directly integrated into workflows and effectively improve efficiency.
How do these capabilities work in real life? We designed a test closer to home to verify this.
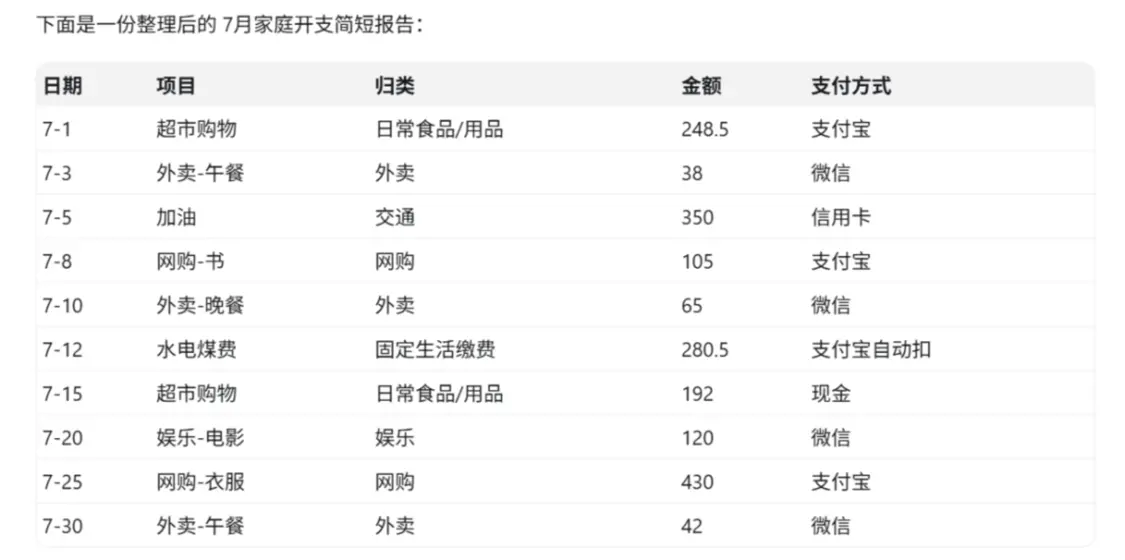
We gave GPT-5.5 several months of messy expense data in various formats, asking it to act as a family data analyst to complete tasks such as organizing data, calculating total expenses, analyzing the proportion of each payment method, and categorizing expenses, and finally generate a recommendation report for family members.
Although this test scenario is simple, it can clearly show whether the AI is truly “usable.” Because household accounting is a daily routine for many people, but records are often written casually and formatted randomly. The “messy” accounting data requires the AI to not only process neat tables but also to “understand” handwritten records, understand the meaning of each expense, and categorize similar items together.
Calculating the total amount, analyzing where the money is spent, and giving savings suggestions actually correspond to a complete thinking process. GPT-5.5 needs to first clarify the information, then find the key points and propose feasible methods, and finally “write a report” requires it to use a way that people can understand and accept to report work.
The test results showed that it accurately merged “Takeout-Lunch” and “Takeout-Dinner,” and proactively suggested that “Alipay automatic deductions” should be uniformly included in “Alipay” statistics, demonstrating its ability to understand messy accounts and user intentions.
GPT-5.5 autonomously organizes the table and provides analysis.
In the analysis, it calculated the proportion and pointed out that spending on the “Shopping” (clothing, books) category was relatively high, and mostly non-essential items. Therefore, it suggested setting a budget for this type of consumption, and the suggestions given were specific and feasible. The final report was also full of human touch. The sentence “slightly control the impulse for online shopping, and our family’s expenses will be easier” conforms to the communication requirements of “showing it to family members,” with a friendly tone and down-to-earth suggestions.
This simple test is equivalent to reproducing the core capabilities examined in the aforementioned GDPval test in a life scenario, and the current results also show that its professional capabilities can be used in real life.
02. Programming Capabilities: From Beginner to Complex, It Didn’t Mess Things Up
In addition to being reliable in daily knowledge tasks, GPT-5.5 also demonstrated good progress in programming, a “hard skill” that requires higher precision.
In a benchmark test testing “agents” (Terminal-Bench 2.0), it achieved a high score of 82.7%. This test simulates performing a series of complex operations in the command line, as if letting the AI complete a multi-step operation and maintenance task by itself. Its score not only surpassed its previous generation (GPT-5.4’s 75.1%) but also significantly exceeded that of its competitor Claude Opus 4.7 (69.4%). This shows that it performs better when it needs to remember steps, debug itself, and persist in completing long-term tasks.
Secondly, there is also progress in handling ultra-long content. In a test targeting ultra-long texts of 500,000 to 1,000,000 characters, its score reached 74.0%, more than double that of the previous generation (36.6%). This means that when analyzing a thick book or browsing a large code repository, it is less likely to “miss” or “confuse” information, and its information retrieval is more accurate and its thinking is more coherent.
Moreover, multiple test results show that when performing the same programming task, GPT-5.5 consumes significantly fewer tokens than GPT-5.4. Even Michael Truell, the co-founder of the code editor Cursor, commented that it is smarter, more resilient, more reliable in invoking tools, and can persist longer when facing complex long-term tasks.
In simple terms, in complex operational scenarios such as programming, the above data shows that GPT-5.5 is not only stronger but also more stable and resource-efficient, making it suitable for handling actual development tasks that are multi-step and time-consuming.
To verify its actual programming capabilities, we conducted a test using a specific development task, starting from scratch to build and gradually upgrade a matching game, and strictly requiring it to use 12 different emoji expressions.
First, we asked GPT-5.5 to generate a complete and runnable matching game.
This requires it to understand the developer’s textual requirements, design the interface, manage the game state, and independently implement the core pathfinding algorithm. It successfully completed this in just a few minutes.
GPT-5.5 generated a small matching game.
Next, we increased the difficulty and asked it to add a “redraw” prop to the game.
The function of this prop is: when used by the player, it consumes “combo” energy to randomly refresh all icons of the same type as the last eliminated one on the board.
To achieve this, GPT-5.5 must do two things: first, modify the underlying data rules of the game to support this new function; second, ensure that the refreshed board layout remains “solvable” and does not cause the player to get stuck. GPT-5.5 successfully wrote this part of the code.
After that, we continued to ask it to add a complete user system to the game, including login, score recording, and leaderboard display.
This step mainly tests whether GPT-5.5 can seamlessly integrate the new function into the existing framework while maintaining the game’s original core gameplay and logic.
It once again successfully completed the task, and showed considerable restraint during the code iteration process, without excessive refactoring or introducing unnecessary changes.
GPT-5.5 executes instructions to adjust game details.
Finally, we pushed the difficulty to a higher level with a real-time competitive mode, allowing two players to compete in real-time elimination in different browsers.
This involves board state synchronization, operation conflict resolution, and network latency handling, a series of typical challenges in multiplayer online games. Faced with such a highly integrated and real-time complex challenge, GPT-5.5 still delivered accurately.
This test from simple to complex shows that GPT-5.5 can handle complex logic and architecture design in real programming tasks, accurately respond to developer requirements, and does not arbitrarily refactor or introduce other code. Even when we asked it to revert to the previous version, it could stably restore to the previous state.
03. High Hallucination Rate: Usable, But Not Without Caution
Despite its impressive performance in real-world testing, GPT-5.5 has not exceeded market expectations by a large margin, and there are still non-negligible risks.
Let’s look at a set of comparative data.
In Artificial Analysis’s private benchmark AA-Omniscience, GPT-5.5’s hallucination rate reached 86%, while Claude Opus 4.7 was only 36%. This means that in the test scenarios specifically designed to detect the boundaries of the model’s knowledge, when GPT-5.5 faces an uncertain answer, its probability of “frankly admitting it doesn’t know” is much lower than that of its opponent, and it is more inclined to generate a potentially incorrect answer.
It should be noted that this 86% does not mean that the model will produce hallucinations in most daily question-and-answer scenarios, but rather its specific behavioral tendency when it reaches its knowledge blind spot. An industry practitioner explained that this may be because GPT-5.5 has a stronger coverage of factual knowledge, but its uncertainty is also more aggressive, and it will guess the answer to uncertain questions. However, when used for tasks requiring high reliability, this indicator still needs to be highly vigilant.
When GPT-5.5 is deployed to “autonomous work” scenarios, this high hallucination tendency may cause risks.
For example, in data analysis and report generation tasks, it may confidently cite non-existent data, fabricate statistical trends, or make decision recommendations based on incorrect facts, leading users to make business judgments that deviate from reality. In programming and debugging, the code solutions it provides may seem reasonable but may not be runnable, or even contain security vulnerabilities, significantly increasing the cost of later troubleshooting and repair.
Moreover, these hallucinations are often presented in a highly confident and logically coherent manner. For users lacking relevant professional backgrounds, this “certainty” output is highly deceptive and requires increased vigilance.
In addition to technical concerns, OpenAI’s business strategy this time also reveals a clear intention: to lock users in with its ecosystem first, and then reap the market with price increases.
On the one hand, GPT-5.5 did not release the API synchronously when it was first launched, but only limited it to its own ChatGPT and Codex, initially locking users into its application ecosystem. On the other hand, the pricing of GPT-5.5 has increased significantly compared to the previous generation. According to official data, processing 1 million tokens with GPT-5.5 costs $5 for input and $30 for output. The previous generation, GPT-5.4, cost $2.5 and $15 for input and output respectively, which means the new generation’s price has directly doubled.
If compared with the current major competitors, Anthropic’s strongest model Opus 4.7 is priced at $5 per million tokens for input and $25 for output. It can be seen that GPT-5.5’s input price is on par with its competitors, but its output price is 20% higher.
Although OpenAI explained that the improvement in token usage efficiency can offset the price increase, making the actual cost for users not significantly increase, the specific cost-effectiveness still needs to be further verified by the industry.
Zhao Jiangjie, a senior Agent practitioner, commented that the release of GPT-5.5 did not form a significant lead, and was not as big an improvement as expected from the widely circulated “Spud” model. However, it still maintains a leading position in agentic and coding capabilities, and the improvement in agentic capabilities is also promoting model vendors to improve model iteration efficiency. OpenAI’s next-generation breakthrough model (GPT-6) is likely on the way.
In conclusion, for ordinary users, GPT-5.5 may be worth trying, but it should not be regarded as an absolutely reliable tool. For enterprise users, they must be cautious before integrating it into core workflows. Once the 86% “confident error” occurs, who will bear the responsibility?