DeepSeek Has a Major Update – It Can Finally See!
DeepSeek has released a significant update, adding multimodal capabilities, specifically image recognition. Following a recent V4 release and price drops, they’ve launched a gray-scale test allowing users to experience a true multimodal V4 version. Researchers are excited, stating DeepSeek finally "has eyes" and is no longer limited.
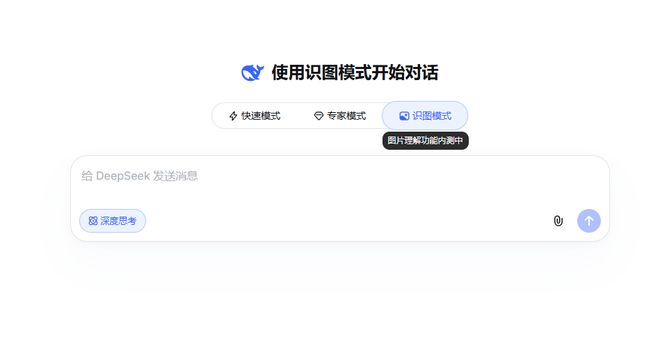
Verified – it’s true.
Those wanting to try it out can now open DeepSeek and take a look.
If you see a “Image Recognition Mode” in the interface, congratulations, you’re one of the lucky testers with access to a free, genuine multimodal V4.
DeepSeek’s researcher, Chen Xiaokang, also posted excitedly, stating their “whale” has finally grown eyes and is no longer a “blind monk”!
Why is everyone so excited? DeepSeek has been criticized for its lack of multimodal capabilities for a long time. Overseas giants like ChatGPT, Gemini, and Claude already have this feature, and domestic models like Doubao and Qianwen also perform very well.
However, this domestically-developed model, which had high expectations, couldn’t even recognize images for years, relying only on OCR (optical character recognition) to identify text within images, resulting in a significantly inferior user experience.
Now, this weakness has finally been addressed.
Let’s get straight to the testing.
First, it has indeed moved beyond traditional OCR and can truly see the entire image, which everyone can rest assured about.
For example, if we give it an image with the words “This is red text” written in blue, traditional OCR would only recognize the text as “This is red text” and wouldn’t identify the color as blue (and might not even recognize the text at all).
However, with visual mode enabled, it can accurately identify it as “This is blue red text” and even seems to understand my humor.
Not only that, but it also has visual reasoning abilities.
Everyone has seen this meme, right? With your intelligence, you should understand what the image is conveying.
So, I sent it to DeepSeek and asked it to analyze the joke.
After some thought, it not only understood it but also provided a localized translation: “Gold Italy,” “Silver Italy,” and “Bronze Italy,” which was quite amusing.
Next, I sent it a blurry picture taken by a colleague while driving, with only some information about the exterior and lighting available.
It still guessed correctly that the car was a Subaru and reached the conclusion after 13 seconds of thinking.
Considering D-teacher is a math expert, we also sent it a math-related meme. To be honest, I almost didn’t understand it – it was a bit too advanced.
D-teacher’s explanation was, as always, perfect.
It not only understood the simple calculation but also recognized the puns: taking the real part means removing the imaginary number “i,” which also removes the “Eye,” thus removing the eyes. And the downward triangle represents the gradient, which is similar to “Graduate,” so it gave the little face a graduation cap.
Those who have forgotten their math knowledge can review it step by step.
I also tested it with some everyday questions, such as where to plug in this 3.5mm jack.
And where to plug in this square USB port.
Although simple, it understood my out-of-focus snapshots and can handle daily tasks.
However, according to my testing, this version of D-teacher isn’t invincible yet.
For example, we gave it a picture of a beautiful Earth night view.
DeepSeek also recognized it clearly, saying the photo was taken from the International Space Station.
But actually, if you flip the photo over, you’ll find it’s a picture of a city under a sunset, an inverted perspective…
Then I gave it to Gemini, a recognized multimodal expert… and it actually figured it out. Is it getting stronger even when it’s being dumbed down?
Has it still not pushed the multimodal king to its full potential, Ha Ji Whale?
Including the recognition of some faces, it occasionally malfunctions. For example, when I gave it a picture of Doubao, it identified it as Luo Xiang, a Bilibili UP master.
And this classic visual illusion problem – aren’t the two balls clearly different sizes? D-teacher, after some thought, told me the two balls are the same size.
However, I also checked its thought process, and it had already realized the right ball was larger, but because it carefully read the question, it thought this was an illusion given to it, so it chose to deceive itself and said they were the same size. Perhaps it’s been over-reinforced through reinforcement learning.
Overall, I’d give it a god-demon duality – it’s amazing when it’s good, and it completely fails when it’s bad.
But then again, DeepSeek has just grown eyes, so we should give it some time to adapt to the world.
Finally, the current AI giant battle has long passed the novice village stage of only looking at benchmarks and text output capabilities.
Coding level, multimodal capabilities, the smoothness of tool calls, and so on, are basically essential.
But D-teacher’s absence in multimodal capabilities has always been a pity. It’s like everyone is working hard, but DeepSeek’s agent capabilities are greatly reduced due to missing limbs.
After all, the vast majority of current models have APIs that are multimodal or at least have image input capabilities.
I also hope DeepSeek can quickly update the image recognition multimodal capabilities to the V4 new model API.
You know, it’s already been fighting with many opponents while blindfolded. Now that the blindfold is removed, the performance with tools like Claude Code, Longxia, and Cowork is expected to improve significantly.
Also, based on DeepSeek’s recent frequency of showing off and gaining attention, there are likely many more combos waiting to be unleashed.
I won’t say more, let’s watch D-teacher perform.